偷拍 Databricks凭什么值620亿好意思元?

 偷拍
偷拍
J轮融资目的为100亿好意思元,咫尺已完成86亿好意思元,公司估值从之前的430亿好意思元跃升至620亿好意思元——这不是某家大家互联网巨头的得益单,而是Databricks,一个相对生疏的大数据公司,近期创造的惊东说念主记载。在系数大数据公司中,Databricks的估值如今牛年马月,已经成为大家市值最高的非上市科技公司之一。
为什么是Databricks?为什么它大略在竞争强烈的大数据规模中,成为少数几个突破重围的赢家之一?为什么,它能在一个充满时间壁垒、成本腾贵、市集竞争强烈的行业里,脱颖而出,且渐渐成为大家市值最高的非上市科技公司?
这些问题,恰是接下来咱们要逐一揭示的。咱们将从Databricks的发展历程、枢纽决策、时间突破到生意化模式和市集定位,一步步判辨它是如何从一个初创公司,发展为大家大数据规模的指点者,进而揭示其见效背后的深档次逻辑和行业趣味。
一切要从Spark提及(2010-2013)
2010年,Hadoop当作大数据的标配,已经在时间圈扎根多年。尽管它为数据存储和离线规划提供了基础架构,但跟着数据量暴增和及时规划需求的崛起,Hadoop的低效性和高蔓延隐患愈发较着。尤其是在需要快速响应与及时数据分析的时期,Hadoop的批处理模式显得粗笨且力不从心。更灾祸的是,它的开发门槛额外高,企业在濒临海量数据时,常常需要付出巨大的东说念主力与物力,才能得回基本的规划才智。
这个时候,市集紧迫需要一种更高效、生动、且大略顺应及时数据流的替代有筹办,大略突破Hadoop的固有局限。
2010年,Databricks团队意志到,大数据的瓶颈不单是是存储和规划才智的短缺,更在于如何高效处理不断变化的及时数据。于是,他们建议了一个果敢的惩办有筹办:内存规划。与Hadoop持久化数据存储在磁盘上的容貌不同,Spark将数据载入内存,利用内存的高速读取才智,透顶冲突了磁盘读取带来的速率瓶颈。

Spark的上风,不仅体当今速率上,它在多个维度上高出了Hadoop:
● 及时性:Spark救援流式处理,极地面心仪了当代企业对及时数据分析的需求。比拟之下,Hadoop的MapReduce只可处理批量任务,无法心仪快速响应的需求。
● 生动性:Spark救援多种数据处理模式——批处理、流处理、交互式查询、机器学习等,给开发者带来了更多招揽,而Hadoop则相对局限于单一的MapReduce模式。
● 规划后果:通过内存规划,Spark提高了规划后果,尤其在机器学习和复杂迭代规划上,推崇出色。传统的Hadoop面对这种需求时,需要大宗的磁盘I/O操作,而Spark则通过数据在内存中径直传递,大幅裁减了规划成本。
Spark的出现,直击了大数据行业的痛点,而况填补了Hadoop无法支吾的空缺。它让大数据时间从单纯的存储规划,迈向了及时、高效、智能的新阶段。这不单是是一个时间见效,更是对行业需求的精确答复。
Spark的时间突破为Databricks带来了巨大的市集后劲,但如何从时间突破跃升为市集占有,成为了接下来的枢纽。2010年,Databricks作念出了一个重要决策——将Spark完好意思开源。这一策略依然发布,坐窝掀翻了时间圈和开发者社区的怒潮。
开源,意味着免费的时间使用,但它背后深藏着久了的政策趣味。Databricks并不指望通过出售Spark赚取径直的许可费,而是通过开源将其打变成时间标杆,并飞速占领大家开发者市集。通过开源,Databricks得回了开发者的爱好,同期也搭建了大家社区化运营的苍劲平台,飞速擢升了品牌的曝光度。
Spark开源后,大家的开发者飞速运转拥抱这一框架。原来被Hadoop困住的开发者,在Spark的生动与高效眼前,看到了更多的但愿。从学术圈到企业界,Spark的用户群体已而扩展到了大家,系数这个词大数据时间社区也运转围绕Spark形成了生态圈。这种社区效应,让Spark的发展速率和应用普及率远超传统生意化软件。
通过开源,Databricks飞速蕴蓄了大宗古道用户,这些用户不仅为Spark提供了绵绵不断的反馈,还通过酬酢媒体、时间博客和论坛为Spark代言。开源神色常常有一个显赫上风,那便是其使用者成为了最佳的传播者。Databricks不仅在时间圈成就了极高的声誉,还通过这些早期采选者的口碑传播,飞速打响了品牌。
开源自身并不料味着莫得生意化的可能,反而提供了一条低门槛进入市集的捷径。Databricks利用了开源政策的见效,不仅引诱了大家企业的关注,更得回了投资者的爱好。本钱看中了Databricks在大数据规模的时间更变与市集后劲,随之而来的是多半融资和快速扩展的生意化程度。
在许多时间公司招揽通过禁闭生意模式来盈利时,Databricks招揽了开源,并奥妙地通过开源社区和时间口碑走出了属于我方的生意化之路。这一决策不仅让它得回了行业关注,也让它得回了本钱市集的爱好。与其说开源是为了免费让渡时间,倒不如说开源是一次精妙的市集渗入,一次从时间圈到生意圈的无缝对接。
通过这种“免费”的容貌,Databricks让Spark成为了大家企业在数据存储与分析上的首选框架,同期为公司翌日的盈利模式打下了基础。它莫得将我方局限于时间销售,而是通过期间赋能与品牌化运作,达成了生意价值的最大化。
从时间到居品,平台化布局与生意化转型
(2013-2016)
在见效冲突大数据时间的“瓶颈”后,Databricks濒临的下一个挑战是:如何让这一切变得易用,而不单是是一个时间圈内的“袼褙”。2013年,Databricks采选了一个具有政策眼光的决策——将Spark时间生意化,并推出了基于云平台的托管办事。
云规划在其时正处于爆发的前夕,但大多数企业对云数据处理仍然抱有费神。尤其在大数据处理方面,企业常常需要干预多半资金来购买硬件开辟和搭建基础措施,运维复杂,且门槛极高。Databricks的云平台办事透顶冲突了这一结巴。通过将Spark和云规划筹商,Databricks提供了一种按需付费的模式,让大数据处理不再是大型企业的专利,而是中小企业也能温暖享用的器具。
这种云+Spark的筹商惩办了几个中枢问题:
● 裁减时间门槛:已往,企业需要我方搭建完整的大数据基础措施,这对许多中袖珍企业来说,险些是不行能完成的任务。而通过Databricks提供的云平台办事,企业不再需要眷注硬件和运维,只需专注于数据分析自身。
● 生动性和可扩展性:云平台自身具有按需扩展的才智,企业不错凭证数据量的变化生动调养规划资源。而这关于传统企业来说,平淡需要雄伟的预算和万古间的蓄意。
● 裁减成本:云平台的按需计费容貌,匡助企业大幅减少了前期本钱开销和运维成本,尤其是关于中小企业来说,这无疑是一项巨大的利好。
Databricks通过这种平台化的生意模式,达成了时间向居品的漂浮,不仅让Spark成为行业标配,更让大数据的应用场景从大企业拓展到了大家范围内的中袖珍企业。这一政策无疑是对大数据时间复杂性和高门槛的精确反击,也为自后续的生意化奠定了坚实基础。
Databricks的云平台依然推出,就飞速得到了市集的认同。2014年,Databricks完成了4000万好意思元的A轮融资,紧接着又告成完成了B轮融资,这两轮融资的见效为公司提供了饱和的资金救援,使其大略加速时间研发和市集扩展。
融资的见效并非无意,而是市集对Databricks时间更变和生意化政策的久了认同。在SaaS模式和云平台托管办事渐渐铺开后,Databricks的业务前程运转引诱本钱的眼光。投资者不仅看中了Spark的时间后劲,更看到了Databricks当作平台化居品在市集结的巨大后劲——从企业级惩办有筹办到大数据的普及化器具,Databricks无疑是站在了这一波时间海浪的最前沿。
融资的同期,Databricks莫得停驻脚步,而是加速了时间更变,尤其是在机器学习和东说念主工智能等新兴规模的布局。通过快速的资金注入,Databricks在算法优化、规划才智以及用户体验上进行了屡次迭代升级。
不单是是Spark,Databricks在云平台的生意化上也作念出了许多更变。它通过SaaS模式,见效冲突了传统大数据平台的局限性,使得大数据处理不单是是存储与规划的需求,更是企业数字化转型的枢纽器具。这少许,尤其对中小企业起到了重要的推动作用。
平台生态与大家化扩展
从单一器具到全产业链惩办有筹办
(2017-2020)
2017年,Databricks从单纯的漫衍式规划框架Spark扩展到端到端数据惩办有筹办,推出了DeltaLake和MLflow。这一溜型标记着Databricks不仅是时间提供商,更是全场合的企业办事商,涵盖了从数据存储、处理、分析到机器学习的各个法度。
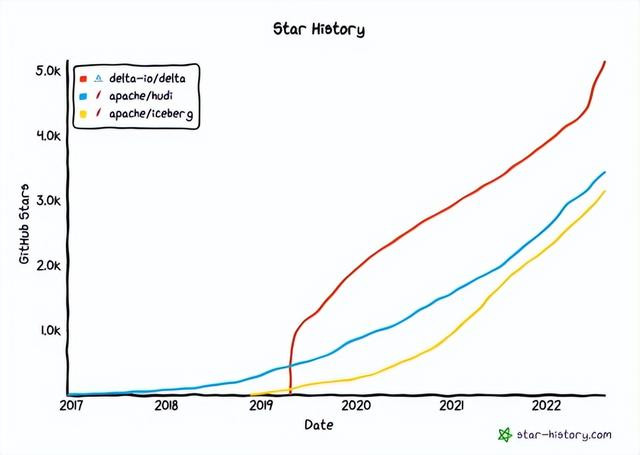
DeltaLake惩办了传统数据湖的数据一致性问题,引入ACID事务救援,极大擢升了数据存储的后果与可靠性。它将数据仓库的一致性和数据湖的扩展性圆善筹商,为企业提供了一个既能救援及时刻析又能存储大宗非结构化数据的高效平台。
MLflow惩办了机器学习人命周期经管中的痛点,简化了模子的开发、追踪和部署经过。它将机器学习的实践经管与分娩化部署无缝衔尾,匡助企业加速AI神色的落地。
Databricks从单一时间平台到详细性数据平台的调养,不单是是居品功能的扩展,更是对行业需求的精确答复。通过整合多个时间档次,它不再只是提供规划才智,而是通过构建数据存储、处理、分析、AI经管的全链条惩办有筹办,飞速占领了大数据与AI交织的中枢市集。这种平台化政策冲突了大数据应用的时间壁垒,为企业提供了一站式办事,透顶改变了行业花样。
Databricks通过与AWS和Azure等大家云规划巨头的深度配合,见效将居品推向大家市集。与顶尖云平台的雅致筹商,不仅让Databricks得以无缝接入大家数据生态,更增强了其时间居品的大家一致性和高可用性。
与云平台的配合为Databricks带来了两个枢纽上风:
跨平台的数据生态整合:Databricks冲突了单一云平台的局限,通过跨平台的兼容性,为大家企业提供了调解的数据惩办有筹办,推动了大家数据生态的互联互通。
大家化市集的加速渗入:与云平台的配合让Databricks在大家市集的时间普及速率大大加速,尤其是在跨国企业中,Databricks成为数据处理的圭臬器具。
在大家竞争日益强烈的环境中,Databricks莫得招揽单打独斗,而是通过与云规划巨头的配合,冲突了行业壁垒,达成了大家化扩展。这一策略的见效,既是对时间更变的推动,亦然对大家市集需求的精确把合手。与AWS和Azure的配合让Databricks在大家范围内成就了苍劲的市集影响力,并进一步擢升了品牌的大家领略度。
从“大数据”到“AI+数据”的调养
(2020-2024)
2020年,Databricks推出了Lakehouse架构,这不仅标记着时间的一次重要飞跃,更是Databricks从大数据到AI+数据的政策转型。Lakehouse冲突了传统数据仓库和数据湖之间的隔膜,通过筹商数据湖的怒放性和数据仓库的结构化才智,为行业提供了一个全新的数据架构。它不仅擢升了数据处理后果,还惩办了长久以来困扰大数据行业的数据一致性和及时性问题。
Lakehouse的中枢上风在于它大略同期处理结构化、半结构化和非结构化数据,这为及时刻析和机器学习奠定了基础。通过引入救援ACID事务的数据存储模子,Databricks提供了一种愈加褂讪可靠的惩办有筹办,大略心仪AI和机器学习对数据一致性的高条目。
跟着AI和机器学习的兴起,市集对大数据平台的需求已经不仅限于传统的数据存储和处理。企业紧迫需要大略救援智能化决策和及时刻析的平台。Databricks凭借Lakehouse架构,见效收拢了这一趋势,飞速将自身定位为一个AI驱动的数据平台提供商,从“大数据”公司转型为全场合智能数据惩办有筹办供应商。
Lakehouse架构的推出,是Databricks对行业发展趋势的精确知悉。跟着生成式AI和大范围机器学习的发展,传统的大数据平台已经无法心仪对及时性和智能决策的条目。Databricks通过这一架构见效捕捉到行业的时间需求,飞速将自身转型为AI+大数据的深度会通者。这种时间进化不仅增强了平台的竞争力,也让Databricks脱颖而出,成为行业的引颈者。
跟着时间和居品不断完善,Databricks的大家化政策进一步加速,绝顶是在欧洲、亚洲和南好意思等市集的扩展。
2022年,Databricks推出了MLflow平台,进一步加强了在AI和机器学习规模的布局。MLflow提供了完整的机器学习人命周期经管,救援模子的考试、部署、监控及优化,这使得Databricks不单是局限于数据存储与处理,更扩展到AI模子经管和机器学习操作的中枢规模。
跟着生成式AI和大模子应用的爆发,Databricks在平台上深度整合AI与数据处理,形成端到端的机器学习惩办有筹办。MLflow平台不仅提供了苍劲的模子经管才智,还为企业提供了全链条的AI惩办有筹办,加速了智能应用的落地。
Databricks的AI政策和MLflow平台的推出,是其在大数据规模的全面转型。这一政策使得Databricks飞速站在了AI+大数据的最前沿。与传统数据平台不同,Databricks的AI+数据深度会通不仅惩办了智能分析和及时决策的穷苦,还心仪了企业日益增长的机器学习和AI模子经管的需求,进一步持重了其在市集结的跳跃地位。
2024年,Databricks完成了86亿好意思元的融资(目的是100亿好意思元),估值突破至620亿好意思元,成为大家估值最高的非上市大数据公司。这一融资的背后,不仅是本钱市集对其更变才智的充分笃定,更标记着Databricks成为大数据行业的整合者和指点者。
跟着融资的鼓励,Databricks不仅得回了资金救援,更得到行业投资者的高度认同。顶级风险本钱的继续投资,体现了市集对其时间更变和生意化才智的强烈信心。每一轮融资的背后,王人在为Databricks膨胀市集、加速时间更变提供坚实的救援。
融资的快速增长与估值飙升,也使Databricks从一个时间公司转型为一个行业整合者。通过收购、时间更变与配合,Databricks构建了一个端到端的大数据处理平台,整合了存储、处理、分析和机器学习等各个法度,掌控了系数这个词大数据生态链的说话权。
Databricks因何取得见效?
总结了Databricks的系数这个词发展历程,接下来,咱们就来总结一下它为什么能成为估值最高的大数据企业。
学生妹avDatabricks的见效并非无意,而是时间突破与政策眼光的圆善契合。从一运转,Databricks就注定不单是一个大数据器具提供商,它久了知悉了数据时间发展的翌日头绪,永恒走在行业前沿,渐渐将我方从大数据的“前驱”推向了AI+数据平台的顶尖地位。
时间更变无疑是Databricks崛起的中枢驱能源,从起初的Spark到如今的Lakehouse和MLflow,每一步王人展现了公司对行业痛点的精确把合手。绝顶是Lakehouse架构的推出,不仅是对传统大数据平台的一次高出,更是对数据一致性和及时性问题的高效惩办。它通过将数据湖的怒放性与数据仓库的结构化才智筹商,见效支吾了大数据处理中一直困扰行业的中枢挑战。跟着AI和机器学习的崛起,Databricks飞速转型,将智能化分析与数据存储无缝筹商,确保了我方不仅大略处理海量数据,还能基于这些数据提供智能决策救援。
然则,时间的突破只是Databricks见效的一部分,市集的尖锐知悉力和精确布局才是枢纽所在。在大家化的竞争花样中,Databricks永恒保持生动应变的政策眼光。通过与大家云规划巨头如AWS、Azure和GoogleCloud的深度配合,Databricks在海外市集上快速站稳脚跟,搭建了一个苍劲的跨国时间生态。这种跨平台、跨地域的政策配合,确保了其居品大略在大家范围内达成一致性和扩展性,也让公司在大家数据革掷中占据了时间和市集的双重上风。
此外,Databricks的融资和本钱策略通常展现了其在市集化转型中的精确决策。它并莫得只是依靠时间去引诱投资,而是通过继续的更变和久了的市集布局,赢得了大家投资者的爱好。其86亿好意思元的融资和620亿好意思元的估值,不仅反馈了其超卓的市集引诱力,更是对其生意模式和经久政策的高度认同。本钱的快速流入加速了其时间研发和大家膨胀,也证实了市集对其AI+数据平台转型的深度信任。
Databricks的见效背后,是时间驱动与政策布局的无缝对接。它通过前瞻性的时间更变,精确捕捉市集趋势,并通过本钱与配合加速了大家化扩展。这种多维度的深度会通,使Databricks不仅在大数据规模占据了指点地位,更通过加速向AI+数据平台的转型,见效引颈了数据时间的新潮水。
国内的大数据公司能学到什么?
在国内,当咱们进行投资或者产业商议的时候,常常会问到的一个问题,便是“谁是中国版的XX”。那么,谁将是中国版的Databricks呢?或者说,思要成为中国版的Databricks,需要作念些什么事情呢?
Databricks的见效为国内大数据公司提供了重要的参考,不单是在时间、大家化布局和本钱运作方面,更在生意模式更变上也有着久了的启示。筹商中国大数据产业的特质和现阶段广博存在的问题,咱们不错从以下几个维度进行模仿,尤其是Databricks如何通过SaaS模式打造可扩展的生意模式,为国内企业提供了至关重要的参考。
1.时间更变与智能化转型:突破国内市集“时间壁垒”
国内大数据公司咫尺边临的最大挑战之一是时间同质化,许多公司仍然专注于基础措施和传统的数据存储、处理,穷乏真高洁略推动智能化、自动化和及时决策的时间更变。Databricks通过深度会通AI和大数据,推出了Lakehouse架构和MLflow等器具,见效惩办了传统数据处理系统在数据一致性和及时性上的痛点。
关于中国的大数据公司来说,思要脱颖而出,就必须走运间更变的说念路。尤其是在大数据与东说念主工智能的筹商上,需要利用AI驱动的数据平台达成从数据存储、处理到智能分析和决策救援的全场合更变。举例,国内的企业不错从Databricks的教会中得回启示,通过整合不同类型的数据(如结构化数据和非结构化数据),开发出智能数据平台,为企业提供更高效的决策救援和精确的市集知悉。
2.大家化布局与配合政策:如何支吾中国市集的“区域性”适度
与Databricks的大家化扩展比拟,中国大数据公司常濒临区域性壁垒。尽管中国市集雄伟,但由于文化、政策、时间生态等多方面的各异,国内大数据公司常常局限于国内市集,冷落了海外化的契机。Databricks的见效恰是通过与大家云规划巨头如AWS、Azure的政策配合,飞速拓展了海外市集,成为大家云规划和大数据规模的中枢玩家。
国内大数据公司应相识到,大家化布局是必须加速的标的。绝顶是在跨国配合和生态共建上,应通过与大家云规划平台的深入配合,借助它们的大家化资源和时间才智,突破国内市集的局限。举例,阿里云、腾讯云和华为云诚然在国内市集竞争强烈,但在海外化方面仍有较大的拓展空间。通过与云规划巨头成就更雅致的配合相干,国内大数据公司大略更快速地进入海外市集,冲突市集范围的瓶颈。
3.SaaS:要勇于云化,不要堕入独有化的“泥潭”中
Databricks的生意模式具有显赫的更变性,其SaaS化模式让它不单是是一家时间公司,而是成为了为企业提供全套数据分析惩办有筹办的办事商。在推出云平台托管办事之后,Databricks冲突了传统大数据办事的门槛,将数据处理才智漂浮为按需计费、生动扩展的SaaS办事。这个举措惩办了大多数企业濒临的时间门槛和腾贵的基础措施成本问题,尤其是中小企业也大略享受到数据分析带来的巨大价值。
国内的大数据公司濒临的一个中枢问题,是盈利模式单一和生意化旅途不明晰。诚然许多公司依靠传统的许可证销售和大数据硬件基础措施进行盈利,但这种模式难以心仪市集快速变化的需求。而通过SaaS模式,Databricks大略达成生动的收入开始,同期提供定制化办事。企业凭证需求购买特定的办事和规划资源,裁减了使用成本,也增强了平台的扩展性和生动性。
对国内大数据公司来说,转型为SaaS平台,不仅不错裁减企业时间门槛,还能通过按需办事和低干预高答复的生意模式,引诱更多的客户,绝顶是中小企业。通过生动的订价策略和办事层级,国内大数据公司不错冲突传统销售模式的适度,达成愈加平淡的市集隐敝。
4.本钱市集与产业整合:幸免中国大数据的“本钱瓶颈”
国内大数据公司濒临的一个凸起问题,是本钱瓶颈。尽管中国的大数据产业范围雄伟,但由于举座时间更变的短板和市集化旅途不解晰,本钱市集关于许多公司投资的信心仍不及。Databricks则通过继续融资和市集考据,飞速扩大了其在大家的市集份额。尤其是在A轮、B轮等多轮融资中,Databricks不仅刷新了估值,更借助本钱推动了大家化政策和时间迭代。
与其依赖传统的融资和本钱注入,国内大数据公司应学会如何利用本钱的力量来推动产业整合。尤其是在中国行将进入的大数据行业整合期,翌日将会出现一系列并购、配合与整合的契机。国内公司必须提前布局,通过本钱市集的积极参与和跨界收购,强化自身的行业说话权。
同期,国内大数据公司还应主动寻找跨行业配合,通过与其他时间规模的跨界会通(如金融、医疗、制造等行业)构建愈加丰富的生意生态。这不仅能带来更多的投资契机,还能促进时间应用场景的更变,达成业务的多元化发展。
综上,Databricks的见效不单是是时间更变和本钱市集的见效,它的生意模式、大家化布局和产业整合策略为中国大数据公司提供了诸多久了的启示。绝顶是在SaaS化生意模式、大家化政策以及产业整合的方面,国内企业不错模仿其教会,加速时间更变、智能化转型,并通过本钱市集布局和跨国配合推动大家化扩展。翌日偷拍,国内大数据公司若是大略在这些规模取得突破,将有望成为海外竞争中的重要力量。
上一篇:反差 匿名咸鱼 龙哥:各位我提议,鹰酱:反对!龙哥:我还没说呢,你反对什么? 下一篇:偷拍 Meta来岁下半年将推出带屏智能眼镜,供应链是挑战




