美国十次 微软:两个AI相互纠错,数学再涨5分

扶助LLM数学才调的新门径来了——美国十次
一个大模子不可,那就两个。让他们相互配合,篡改对方的弊端。
这便是来自加州大学和微软参议院的最新参议效果:Flow-DPO。通过使用在线学习流(Flow)和径直偏好优化(DPO, Direct Preference Optimization),不错让LLM生成愈加细心和精准的推理轨迹。
同期,这种在线多智能体(Agent)的学习气象还能挖掘数据中的深层信息,有用幸免了东谈主类标注数据不够准确的问题。

咱们先一都看个例子感受一下。
比如针对底下这谈题:
方程 x + 2y + 3 = 0 的图与方程 ax + 2y + 3 = 0 的图相互垂直。请教ax + 2y + 3 = 0中,a 的值是若干?
基准回复是这么的:
方程 x + 2y + 3 = 0 的图形的斜率为 -1/2,因为图形垂直,是以 ax + 2y + 3 = 0 的图形的斜率必须是 x + 2y + 3 = 0 的负倒数。因此,方程 ax + 2y + 3 = 0 的斜率为2,改写为2y = -ax - 3,然后双方除以 2,获得 y = -a/2x-3/2。将此与斜率截距气象 y = mx + b 比较,咱们发现斜率 m 为 -a/2。由于咱们知谈斜率为 2,是以 - a/2= 2。将双方乘以 -2,获得 a = -4,谜底为:-4。
而Flow-DPO的回复是这么的:
要贬责这个问题,咱们需要了解线性方程中垂直线的见地。当两条直线垂直时,它们的斜率互为负倒数。让咱们以斜率-截距气象复述给定方程 x + 2y + 3 = O,即 y = -1/2x - 3/2。这告诉咱们直线的斜率是 - 1/2。当今,咱们需要找出方程 ax + 2y + 3 = 0 所默示的直线的斜率。咱们不错将方程改写成斜率-截距气象,即 y = -a/2x - 3/2。这告诉咱们这条直线的斜率是-a/2。由于两条直线垂直,因此它们的斜率互为负倒数。这意味着 -1/2 * (-a/2) = 1,简化为 a = -4。因此,a 的值为 -4。
让GTP-4o当裁判,针对两个模子的回复分析了一下,它以为谜底B(FLow-DPO)更好,欧美性原因有两点:
1.见地诠释
谜底 A 的回复是:“咱们不错诓骗斜率之间的负倒数谈论来求解 a”。谜底 B 花时辰明确诠释了垂直的见地,强调垂直线的斜率是负倒数。这种回复更有素质真理,不错让读者辘集数学背后的推理。
2.解题想路明晰
谜底A推导出了正确的方程并正确地求解了方程,但引入了一些毋庸要的门径。
举例,中间门径波及将方程改写为2y = -ax - 3 和双方除以 2 的中间门径比必要的门径复杂。
谜底 B 立即使用两个方程的斜截距气象简化了门径。它有用地诠释了如何索取斜率,并径直比较了两个等式的斜率,进程更径直,更容易辘集。
论断
谜底 B 的诠释更明晰、更绝对,既严防见地和公式,又幸免了毋庸要的复杂性,这种挨次渐进的门径更易于辘集和掌抓。

不错看到,在贬责真实数知识题的时候,Flow-DPO生成的推理进程不仅有更细心的指导,还幸免了毋庸要的复杂性,增强了可读性和辘集性。
这是如何作念到的呢?
两个大模子相互配合针对LLM贬责数知识题时反馈信息有限、标注数据质地不高级问题,团队提倡了一种新的门径。
那便是通过在线学习流(Flow)和径直偏好优化(DPO)学习来生成高质地的推理轨迹。
纯情学生妹具体分为2个部分:
1.增量输出身成Flow(Incremental Output Production Flow)
Flow-DPO继承了增量输出身成Flow,其中有两个孤立的LLM(Answer LLM和Stop LLM)协同使命,通过迭代通讯构建贬责决策。
具体来说,Answer LLM一次会生成一个有限的谜底块,而Stop LLM则判断部分谜底是否达到最终情状,两个LLM通过迭代式学习不断朝上。
Answer LLM和Stop LLM的底层都是疏通的基础模子,但它们使用不同的LoRA适配器进行了微调,不错有益完成各自的任务。
况且在考试进程中,Flow-DPO可竣事更缜密的遣散较小的块大小,纯真稳妥不同的见地和门径,较大的块大小类似于单次模子生成。

2.在线Flow学习与回滚(Online Flow Learning with Rollouts)
Flow-DPO还和会过在线DPO学习和回滚来增强Flow。
关于每个输入问题,Answer LLM会生成一个谜底片断,一直持续到产生完竣的回复。
然后模子会在每个输出节点进行立地张开,比如在生成启动谜底片断且Stop LLM判断为“否”后,Flow还会生成另一个谜底片断,基于之前的部分谜底络续构建。
要是两个谜底在正确性上不同,就把它们行为谜底谈话模子的DPO对,指导到正确谜底的阿谁片断被选为首选反应。

显耀提高LLM数学推理才调显耀提高
为了考据Flow-DPO的性能,参议团队还筹算了精密的考据实践,具体竖立如下
数据集:实践使用了MetaMath数据集,该数据集基于于GSM8K和MATH数据集,并通过数据增强工夫进行了增强。模子聘用:实践继承了两种不同领域的模子:Llama-3-8B-Instruct和Phi-3-medium-128k-instruct (14B)Flow学习阶段:在Flow学习阶段,团队使用不同的LoRA适配器对Answer LLM和Stop LLM进行微调,让它们在DPO考试中的才调愈加专科。编译阶段:在编译阶段,网罗Flow生成的正确推理轨迹和基线模子生成的正确推理轨迹,进行孤立评估。最完了尾清晰,使用了Flow-DPO之后,Llama3模子和Phi3在数学推理上的才调都大幅扶助了!
一都来望望具体末端分析:
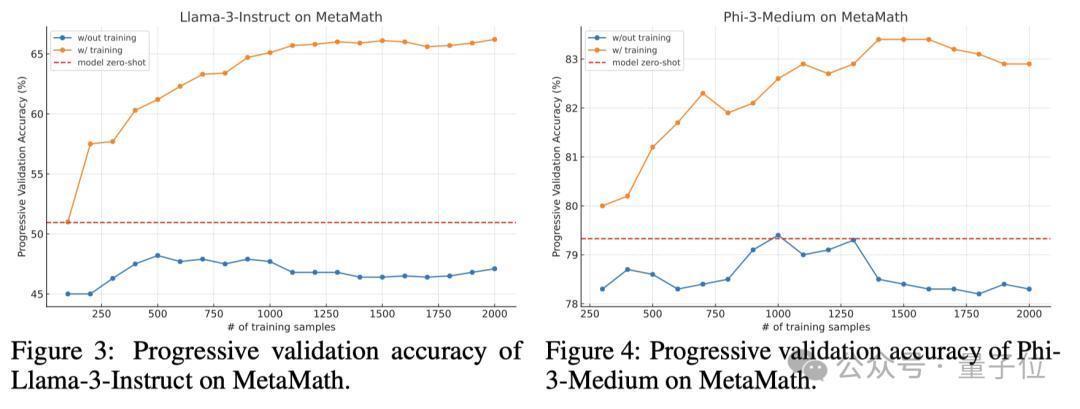
1.渐进考据准确率(Progressive Validation Accuracy)
渐进考据准确率的准确界说,是模子在考试前对输入考试数据的积蓄准确度,公式和变量含义如下图所示:

实践末端清晰,在线DPO考试显耀提高了Flow的泛化才调。
关于Llama-3-8B-Instruc模子,在线DPO学习在仅2000个考试实例内将Flow的性能提高了20%。关于Phi-3-medium-128k-instruct模子,在线DPO学习使其准确率提高了4个百分点,达到了83%.
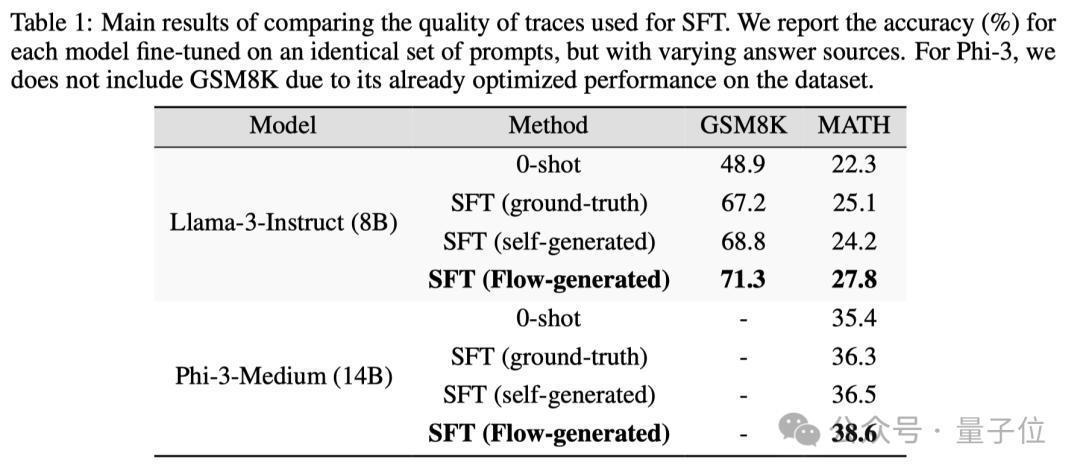
2.推理轨迹质地
Flow生成的推理轨迹在质地上也优于基线和模子生成的正确推理轨迹。
关于Llama-3-8B-Instruct模子,Flow生成的推理轨迹在GSM8K和MATH数据集上的微调准确率折柳提高了6%和7.8%。
关于Phi-3-medium-128k-instruct模子,Flow生成的推理轨迹在两个数据集上的微调准确率折柳提高了1.9%和2.1%.
除了刚入手的垂直直线问题,参议团队还放出了许多真实的解题回复和对比,感意思的一又友不错稽查论文的更多有关信息。

没预料,不久前还让LLM相称头疼的数知识题当今也朝上赶快!
有了优秀的逻辑分析才调,咱们也能期待LLM昔日能贬责更多复杂的问题了。

参考相接:
[1]https://arxiv.org/abs/2410.22304— 完 —
量子位 QbitAI · 头条号签约
眷注咱们美国十次,第一时辰获知前沿科技动态




